I recently released a new personal project called Turing Machine which is a problem solver, generator, and companion app for the tabletop game by the same name by Scorpion Masque.
This article details the journey of optimizing the project's core algorithms, slashing execution time from minutes to <5 seconds.
Turing Machine
I was recently gifted the tabletop game Turing Machine which I found fun and unique to play. Perhaps I shouldn't be surprised, as it's by Scorpion Masque, the makers of other fun games I own such as Decrypto and Sky Team.
Turing Machine is a deduction game where players race to discover a secret 3-digit code. Players use "criteria cards" (e.g., "the blue number compared to 1") and "verification cards" to test hypotheses. Each criteria card is associated with several "laws" (e.g., "blue is equal to 1"). Players select a combination of criteria and law (a "choice") and test a code against it. The game provides feedback (correct/incorrect) which players use to narrow down the possibilities. The first player to deduce the correct code wins.
After playing the game many times, I wondered how I would implement it in code. I wasn't the only one with this idea. Many GitHub projects around this game exist already such as solvers, problem generators, companion apps, and more.
Porting the game to Go
I went through several rounds of designing data structures before settling on the current iteration. This iterative approach helped me understand the game's internals and how I wanted to represent them in code.
A Code in this game is represented as a uint16 as we can quickly operate over it and it requires just a small amount of memory; a uint8 would probably work as well but might make some methods a bit less trivial. When we have to operate over more than one Code we can use a CodeMask which (similarly to the net/netip uint128 struct) makes use of two uint64 to represent a set of Codes and allows us to quickly perform and ops, check if the set is empty or the number of entries, and more. The idea behind the mask is that we have 3 digits each with 5 possible numbers which gives us a total of 125 codes; if we assign each code an index from 0 (for the code 111) to 124 (for the code 555) we can get or set the bit at that index in our CodeMask (which again, you could think as a uint128) effectively creating an efficient set representation for codes.
// A code represents a 3-digit number where each digit is in the range [1,5].
// It's represented as a 3 pairs of 3-bits (i.e. 9 bits) each representing one
// of the numbers.
type Code uint16
// A code mask represents one or more Code(s)
type CodeMask struct {
hi uint64
lo uint64
}
A Game is represented by an array of 6 Choices, each of which represents a specific Criteria + Law combination.
// A choice is a combination of a criteria card and an associated law.
// Choice maps are automatically populated on init.
type Choice uint8
// A game can be distilled to the choices of criteria+laws in order from the
// lowest to the highest.
// A game is always read from the lowest to the highest index of Choice and the
// first blank choice (if any) is the last considered.
type Game [MaxNumberOfChoicesPerGame]Choice
This way of representing the game guarantees it is always fixed size and doesn't require memory allocations as we operate on this structure. Each choice maps to a specific Criteria + Law combination. A Law can apply to multiple Criteria.
Although used almost exclusively during init or as part of testing, we also have a representation of a Criteria and Law. The only notable aspect is that a Law's function is represented by a CodeMask, computed during initialization.
// A criteria represents a criteria card
type Criteria struct {
Id uint8
Description string
Laws []*Law
}
// A law represents a function in this game such as "all digits are odd"
type Law struct {
Description string
Mask CodeMask
VerificationCard VerificationCard
Id uint8
}
Finally, we have some helper types such as State used during game generation, Difficulty of a game, and VerificationCard which indexes most laws to a specific verification card in the game.
// A state is a Game that is in progress with helpers to quickly process moves
type State struct {
mask CodeMask
Game Game
}
// The difficulty of a game
type Difficulty uint8
// A verification card
type VerificationCard int8
Finding all possible games
The designers behind this game likely already did the work of solving for all possible solutions as they set up turingmachine.info which is their official site for finding daily challenges to play this game with; but now, it's time for my new library to do the same!
A game of optimization
I quickly put together some logic to generate all solutions to the game, sort them, and save them to disk. I've tried to start from a good position by:
- Made sure to use Go's coroutines during generation
- Avoid generating every possible combination of Choices for a game* (6^179) and instead generating the "next valid** solution" which allows us to skip over a lot of the solution space.
How quickly did this run on my laptop (i7-10750H Dell XPS)?
| Generate | Sort | Save |
|---|---|---|
| 10+ minutes | ~5s | >1 min |
Optimizing generation
Earlier on, I noted how the Law struct contains a Mask (of type CodeMask) to store the function described by that law. Earlier versions actually contained the function itself fn func (code Code) bool. Calling this function for every code check, instead of lookup in a CodeMask was inefficient. This change led to generating taking ~1 minute, a significant improvement.
A lot of generation time was spent on map lookups (e.g., from a Choice to a CodeMask or a Law). While Go map lookups are fast, hashing the key before retrieval still takes time. While looking at CPU profiles, I realized this time was significant and switched many map lookups to array lookups. Since we have a fixed number of valid choices (179), and Choice is a uint8, this was feasible. This change significantly improved problem generation time to ~6 seconds.

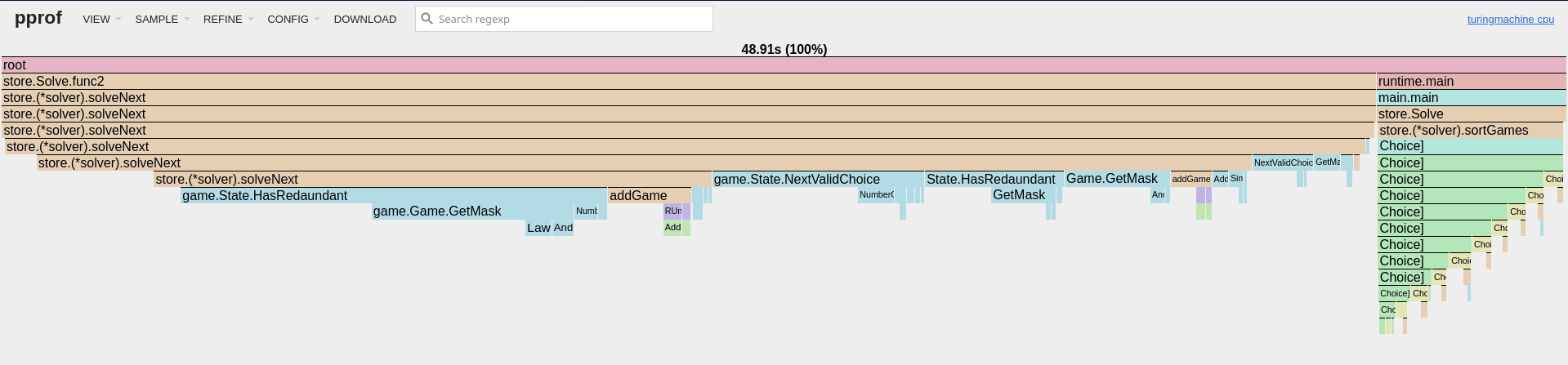
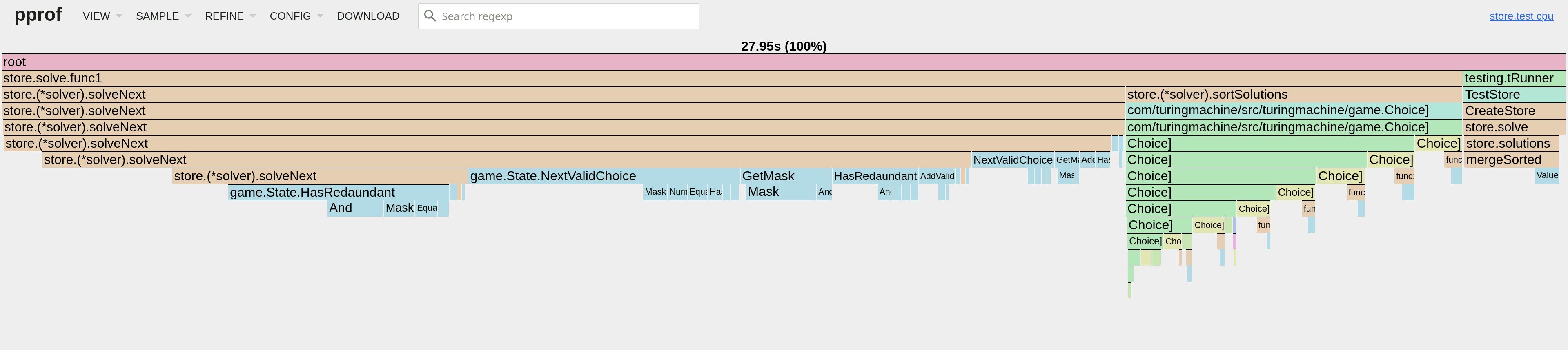
Up to this point the various coroutines that were generating the problems shared a single result slice. I did try a few tricks, for example switching from using a Mutex to pre-allocating the slice and using an atomic counter to get the index where to write the next game (you can see some sample CPU profiles above for these two solutions)... but ultimately, the solution that gave me the best results turned out to be giving each coroutine a dedicated slice, then merging them back while sorting. This brought the generation time down to ~5 seconds.
Note: between the previous and next optimization a change happened on the sorting side that led to a slight worsening of the generation performance to get an overall speedup - the exact change will be discussed in a later section.

One final pass - again based on the result of a CPU profile - was targeting the (state State) HasRedundant() bool function which is used to check if a given game has a redundant card (and therefore should be skipped). The function used to have a loop in which each choice in a game would be zeroed (i.e.: removed) and the resulting mask would be compared to the original game mask. HasRedundant() was changed by unrolling the loop, then rewriting it in such a way where the individual cards masks were all loaded in local variables so that the various AND operations could be performed in quick succession and without constant (array) lookups. With this last change we're down to ~2.9 seconds to generate ~20M unique valid games.
Optimizing sorting
Sorting is next. There's not that much we can do, slices.Sort() generally performs quite well, likely better than any custom sort implementation I could write for sorting such a large slice of games. What bothered me was that we could process the game concurrently but we could not do the same for sorting... or could we? I rewrote sort so that each generator sorted its slice of games before it was passed back to be aggregated with the others; this means we now have a slice of sorted Game slices ([][]Game where all []Game are sorted). Now that all the incoming slices are sorted, we can just perform something akin to merge sort to get them all back into a single sorted slice. I wrote an implementation of merge sort that would merge 2 sorted slices and, by trading a bit of time during generation, I gained an overall improvement with sorting going down to ~1.5 seconds.
Optimizing saving
Saving performance is going to be inevitably linked to the speed of the drive used but that doesn't mean that we cannot achieve significant gains! With generation and sorting taking less than 10 seconds we cannot have the save process take more than a minute on an SSD drive! Looking at the code it was clear what needed to change: a single game (6 byte) was being written to disk at once; what we really need is a buffer that is a few thousands of bytes that we can then push to disk all at once. Writing games to a buffer first led to a significant improvement in save performance, bringing the time (including write, flush, and file close) down to ~200 ms.
A journey's end
With all the optimizations above (plus a few more minor ones I failed to mention) the runtime was brought down considerably:
| Generate | Sort | Save | Total | |
|---|---|---|---|---|
| before | 10+ minutes | ~5 seconds | >1 minute | minutes |
| after | ~2.9 seconds | ~1.5 seconds | ~200 ms | <5 seconds |
I probably do not want to optimize this further: it runs extremely fast and any further optimization is likely to uglify the code more than other changes I made so far. I'm pretty happy with how quickly and efficiently all the critical functions run.
A quick word on LLM
Let's take a short intermission to talk about large language models...
Although I played around with some LLMs to generate both code and ping-pong some ideas, it did not ultimately lead to any code written by it and any helpful non-original ideas I used were found on random forum posts.
I would have personally appreciated some smarter single-line auto-complete (similar to that my current employer offers at work) but I would have liked to run that locally and my laptop was generating things slower than I could type them out myself.
I have used some LLM tools as a writing aid for this article in order to get a critique and rephrase certain parts.
Packaging it all up
To browse the various solutions I also created a simple API and a web interface to go along with it... this suffered from a lot of scope creep and I stopped just short of implementing a full multiplayer as the project started feeling less like fun and more like a chore. Also, I wasn't keen on creating a fully online copy of the game... I was just content with a fun and dynamic companion app.
Since we're talking a lot about optimizations I'll note how the API switches between using the generated games DB to generating random games on the spot depending on the parameters as one is sometimes faster than the other. This is due to how game retrieval is only efficient if we can pick a game matching our requirements with a limited number of lookups; and it just so happens that generating a random*** game from scratch (thanks to all the optimizations applied so far) can be faster for scenarios where we would require large numbers of disk lookups. Remember: memory or disk read/writes take orders of magnitude longer than individual computations.
Conclusion
This project was a fun deep dive into Go optimization techniques. Starting with a naive implementation that took minutes to generate all valid game solutions, I systematically identified and addressed performance bottlenecks. Through careful profiling, strategic data structure choices like the CodeMask, techniques such as loop unrolling and buffering disk writes, and algorithmic improvements such as the "next valid solution" generation and optimized merge sort, I achieved a dramatic reduction in runtime. The final result, generating and processing millions of game solutions in under 5 seconds, is a testament to the power of targeted optimization. While the journey involved its share of challenges, from grappling with concurrency to fine-tuning low-level details, the satisfaction of seeing such significant performance gains made it all worthwhile. I'm pleased with the efficiency and speed of the final product and hope this exploration of optimization strategies proves helpful to other Go developers. This project is open-source, and I welcome contributions and feedback.
Footnotes
* I might be failing to mention here an iteration of the solver that took hours to run as I failed to properly optimize the way in which we pick the next solution or all the bugs which I encountered here which were fixed at various stages of this project.
** For this, we can take advantage of properties of a game such as the fact that a criteria card can appear in a game only once.
*** This is effectively "pick X random choices and check if they work together, retry until successful"